Design Flaw
Leave a reply
Dandelion Wine
by Ray Bradbury, 1957

Great summer read. I read this while at the beach in Florida. It is a series of related short stories about the defining events in a boy’s childhood. Good view into the boyhood psyche and a reminder about how children view the world (or at least used to; I don’t know how smartphone children view the world).
From a 2004 paper by Gaba et al:
If a contestant has the opportunity to modify the distribution of her performance, what strategy is advantageous? When the proportion of winners is less than one-half, a riskier performance distribution is preferred; when this proportion is greater than one-half, it is better to choose a less risky distribution. Using a multinormal model, we consider modifications in the variability of the distribution and in correlations with the performance of other contestants. Increasing variability and decreasing correlations lead to improved chances of winning when the proportion of winners is less than one-half, and the opposite directions should be taken for proportions greater than one-half. Thus, it is better to take chances and to attempt to distance oneself from the other contestants (i.e., to break away from the herd) when there are few winners; a more conservative, herding strategy makes sense when there are many winners.
Applications to academia:
For example, if a school wants to be more innovative and nurture high-risk, high-payoff “big ideas,” it should decrease p (of tenure) for junior faculty…
There are also implications regarding the type of individual who might join the organization. For example, consider a new Ph.D. entering academia with a choice between a school with moderate research expectations and reasonably high p (of tenure) and a top research school with low p but greater rewards associated with winning the tenure contest. An organization wanting to minimize the chance of very low performance and/or to attract people who prefer to stay on well-trodden paths should set p high, whereas an organization wanting to increase the chance of especially high performance (at the cost of an increased chance of especially low performance) and/or to attract people who are competitive and like the challenge of striking off in new directions should set p low.
“Get a fall guy.” I used to like Cris Carter.
Reggie, don’t go to the dark side!
Probably an overreaction. Funny.
Predisastered:
Reminds me of my old volleyball paper:
Foundation
by Isaac Asimov, 1951

I’m spreading out the reading of the Foundation series over a few months. Foundation is the first novel in what was originally a trilogy. I like Asimov’s writing and science fiction. This one deals with the evolution of an empire as innovation stagnates and leadership weakens. The Foundation is created to stave off tens of thousands of years of dark ages when the empire inevitably crumbles. I think the evolution of economics and psychology in the Foundation reads a lot like Animal Farm, by Orwell, published in 1945.
I read 212 research papers in the 12 months following June 2014. Some were for coursework. Some were for research. Some were just because I felt like it.
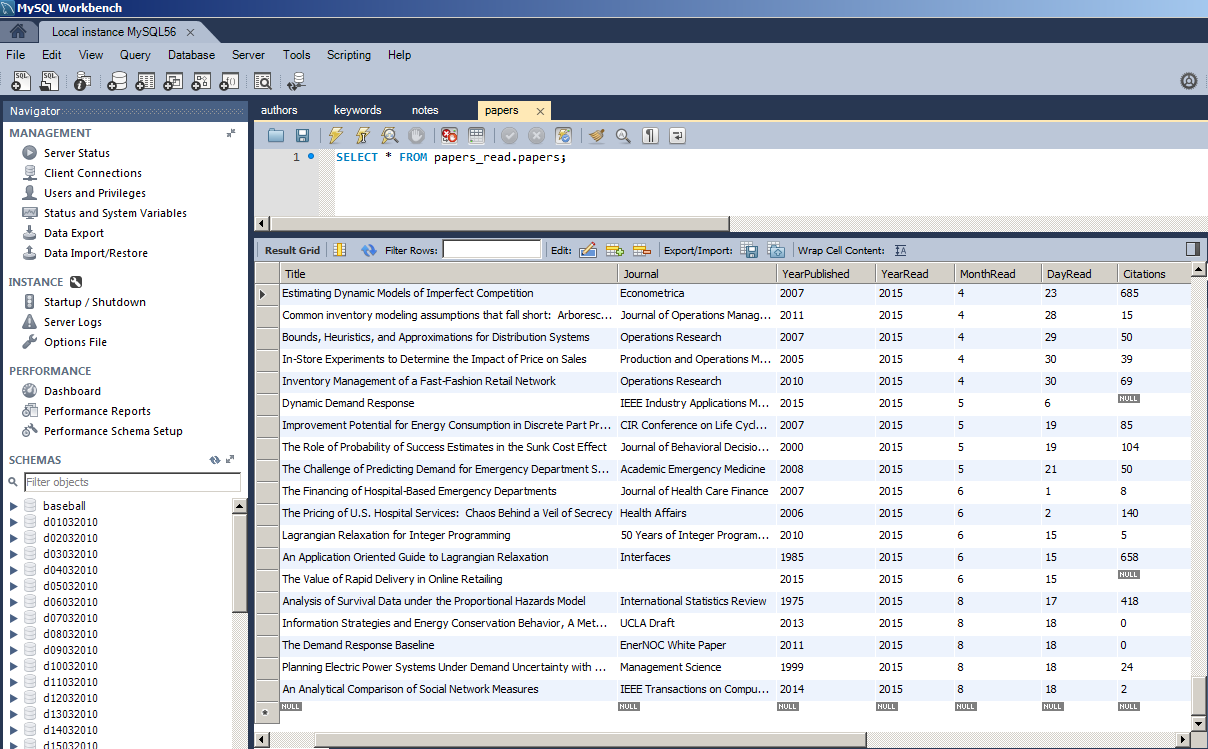
As anyone who knows me will tell you, my memory for details is not very good. I’m more of a big picture person. So I worry that I won’t retain much from this giant expenditure of time in reading research papers.
I’d like to describe my current system for saving information from research papers for later use. I have a few use cases for this effort:
Use Case 1: Upon writing a research paper, I want to know which papers I’ve read about the topic so that the literature review moves more smoothly.
Use Case 2: When I go to interview for a job at a university, I’d like to know which papers I’ve read from the faculty there. This may provide opening discussion topics.
Use Case 3: I’d like to save my ideas for follow-up actions (after reading papers) in one place.
Use Case 4: When topics in diverse fields reference the same topic, I’d like to be the person to connect the fields.
LOW TECH SOLUTION:
Last year, I saved the first page of every research paper I read in a binder with my hand-written notes on the first page. This provides a form of storage, but it is not at all searchable or cross-reference-able.
HIGH TECH SOLUTION:
This year, I designed a template that contains all the information about a paper that I want to save. I then designed an import process to port this information from the template (text document) to a database that I can query easily. Here is my process for that, including code and database setup:
1. Install MySQL (https://www.mysql.com/) locally on your most-used computer.
2. Create a database called “papers_read”.
3. Run the code in the attached files to create your database tables (The code is attached here as .txt because my website doesn’t allow me up to upload .sql. Just fix the extension so it is “.sql”): papers, authors, keywords, and notes.
4. Create a folder on your computer called “Paper Notes to Upload”. Put the following template file in the folder: template.
5. Install Python and the related library MySQLdb.
6. Save this Python code wherever you save your code: addNewFromTemplate (again, the extension has been changed to .txt for security reasons. Rename to .py). Update the “folder_to_add” directory in the code to point to the folder you created in step 4.
Now, whenever you read a paper:
A. Fill out the template with the paper details, and save the text file as something OTHER than ‘template.txt’ in the folder created in step 4.
B. When it is convenient (there may be multiple files to upload in the “Paper Notes to Upload” folder), run the Python code. This will upload your notes to the database.
C. Move the paper notes out of “Paper Notes to Upload” folder after uploading. If you run the code again with them still in the folder, they will be uploaded again.
Some notes on the template:
-Do not use colons in any of the fields you save, as the code uses colons to parse the document. If the title of the paper has a colon in it, use a comma instead.
-I grab the number of citations from Google Scholar by searching for the title of the paper.
-“Comma-separated Keywords” is for you to list the keywords in the paper, with a comma between each.
-In the authors section, be sure to delete any extra/unused author spaces. Feel free to add more if necessary, following the pattern of the first 6.
-Under Reading Details, the Hours to Read is how long it took you to read the paper in hours (can be decimal). The Not Read is a place to list sections/pages not read. The Skimmed is a place to list sections/pages quickly skimmed for which another read would be necessary to understand all the details. Reason Read is a reminder of why you read the paper. Methodology Used lets you list the methods used in the paper (i.e. survey, lab experiment, mathematical model, optimization, etc.), if that is relevant to your work.
-Under My Notes, “Keywords for me” lets you list more keywords that the paper did not list itself (comma-separated, again). FollowUp lets you list actions that should be done after reading the paper. Note1 through Note5 let you list notes to yourself about the paper. Limit each note to 200 characters and do not add more. No need to delete unused notes.
I hope this helps. It’s the process I use. Feel free to alter to fit your needs. Let me know if you use it and if you have any questions. All the code is my own and it is fairly fragile (but works for me); feel free to let me know if you have issues or a better solution.
Presentations I will be giving at INFORMS 2015, Nov 1-4:
1. Cluster: Manufacturing & Service Oper Mgmt/Sustainable Operations
Session Information : Sunday Nov 01, 13:30 – 15:00
Session Title: Incentives and Investment in Renewable Energy and Energy Efficiency
Title: Demand Response, Energy Efficiency, And Capacity Investments In A Production Line
Presenting Author: Eric Webb,Graduate Student, Indiana University
Co-Author: Owen Wu,Indiana University
Abstract: Demand response (DR) programs incentivize industrial firms to halt production during times of peak electricity demand. We consider a firm faced with the option of investing in energy efficiency (EE) improvements at individual machines on the production line. When viewed in isolation, EE incentives may not be enough to induce the firm to invest in the socially optimal level of EE, due to the loss of DR revenue after installation. We suggest a new policy for EE incentives in light of DR.
2. Cluster: Manufacturing & Service Oper Mgmt/Healthcare Operations
Session Information: Tuesday Nov 03, 16:30 – 18:00
Session Title: Patients and Practice: Using the Right Resources to Deliver Care
Title: Incentive-compatible Prehospital Triage In Emergency Medical Services
Presenting Author: Eric Webb,Graduate Student, Indiana University
Co-Author: Alex Mills,Assistant Professor, Indiana University
Abstract: The Emergency Medical Services (EMS) system is designed to handle life-threatening emergencies, but a large and growing number of non-emergency patients seek healthcare through EMS. We evaluate the incentives underlying prehospital triage, where EMS staff are allowed to identify patients that could be safely diverted away from the hospital and toward appropriate care. Continued transition from fee-for-service payments to bundled payments may be necessary for prehospital triage implementation.
3 (I will be presenting). Cluster: Behavioral Operations Management
Session Information: Wednesday Nov 04, 08:00 – 09:30
Session Title: Behavioral Models in Operations Management
Title: Linking Customer Behavior And Delay Announcements Using A Probability Model
Presenting Author: Qiuping Yu,Assistant Professor, Indiana University
Co-Author: Kurt Bretthauer,Professor, Indiana University
Eric Webb,Graduate Student, Indiana University
Abstract: Service systems often offer announcements to customers about their anticipated delay. We empirically examine how announcements affect queue abandonment behavior using a duration model accounting for potential behavioral factors. Our results show announcements induce the reference effect and customers exhibit loss aversion. We also find evidence indicative of the sunk cost fallacy. We then provide insights for staffing and delay announcement policy accounting for observed behavioral factors.
4 (poster). Title: Using Past Scores and Regularization to Create a Winning NFL Betting Model
Presenting Author: Eric Webb, Graduate Student, Indiana University
Co-Author: Wayne Winston, Professor, University of Houston
Abstract: Is the National Football League betting market efficient? We have devised a profitable betting model that would win 52.9% of the 7,554 bets against the spread it would have made over 33 seasons. Scores from previous weeks are used to estimate the point value of each team’s offense and defense. These values predict next week’s scores, and a bet is placed against the advertised spread. The sum of squares of offensive/defensive point values are constrained to be less than a regularization constant.
My poster will be presented 12:30-14:30 on Monday, Nov. 2, so I have presentations every day of the conference. Come see me!